Esta sección cubre los conceptos básicos de los gráficos de computación sin el contexto de TensorFlow. Esto incluye la definición de nodos, bordes y dependencias, y también proporcionamos varios ejemplos para ilustrar los principios clave. Si tiene experiencia y / o se siente cómodo con la computación de gráficos, puedes saltar a la siguiente sección.
Fundamentos de la gráfica (Graph Basics)
En el núcleo de cada programa TensorFlow se encuentra el gráfico de cálculo que se describe en el código con la API TensorFlow. Un grafo computacional, es un tipo específico de grafo dirigido que se utiliza para definir, como era de esperar, la estructura computacional. En TensorFlow es, en esencia, una serie de funciones encadenadas, cada una pasando su salida a cero, una o más funciones a lo largo de la cadena. De esta manera, un usuario puede construir una transformación compleja en los datos mediante el uso de bloques de funciones matemáticas más pequeñas y bien entendidas. Veamos un ejemplo escueto.

En el ejemplo anterior, vemos el gráfico para la adición básica. La función, representada por un círculo, toma dos entradas, representadas como flechas que apuntan a la función. Produce el resultado de sumar 1 y 2 juntos: 3, que se muestra como una flecha que apunta hacia afuera de la función. El resultado se puede pasar a otra función, o simplemente se puede devolver al cliente.
También podemos ver este gráfico como una simple ecuación:

Lo anterior ilustra cómo se utilizan los dos bloques de construcción fundamentales de gráficos, nodos y bordes cuando se construye un gráfico de cálculo. Vamos a repasar sus propiedades:
- Nodos (Nodes): Normalmente dibujados como círculos, óvalos o cajas, representan algun tipo de cálculo o acción que se realiza en o con datos en el contexto del grafo. En el ejemplo anterior, la operación "agregar" es el único nodo.
- Bordes (Edges): Los bordes son los valores reales que se pasan hacia y desde Operaciones, y normalmente se dibujan como flechas. En el ejemplo de "agregar", las entradas 1 y 2 son ambos bordes que conducen al nodo, mientras que la salida 3 es un borde que sale del nodo. Conceptualmente, podemos pensar en los bordes como el enlace entre diferentes Operaciones, ya que transportan información desde uno nodo al siguiente.
Ahora, aquí hay un ejemplo un poco más interesante:

¡Hay algo más en este gráfico! Los datos viajan de izquierda a derecha (como lo indica la dirección de las flechas), por lo que vamos a desglosar el gráfico, comenzando desde la izquierda.











¡Hay algo más en este gráfico! Los datos viajan de izquierda a derecha (como lo indica la dirección de las flechas), por lo que vamos a desglosar el gráfico, comenzando desde la izquierda.
- Al principio, podemos ver dos valores que fluyen en el gráfico, 5 y 3. Pueden provenir de un gráfico diferente, ser leídos desde un archivo o ingresados directamente por el cliente.
- Cada uno de estos valores iniciales se pasa a uno de dos explícitos nodos de "entrada", etiquetados a y b en el gráfico. Los nodos de "entrada" simplemente pasan los valores que se les asignan; el nodo a recibe el valor 5 y envía ese mismo número a los nodos c y d, mientras que el nodo b realiza la misma acción con el valor 3.
- El nodo c es una operación de multiplicación. Toma los valores 5 y 3 de los nodos a y b, respectivamente, y genera el resultado de 15 en el nodo e. Mientras tanto, el nodo d realiza la adición con los mismos valores de entrada y pasa el valor calculado de 8 a lo largo del nodo e.
- Finalmente, el nodo e, el nodo final en nuestro gráfico, es otro nodo "suma/agregación" recibe los valores de 15 y 8, los suma y arroja 23 como resultado final de nuestra gráfica.
A continuación veremos cómo sería la representación matemática de la gráfica anterior, este podría verse como una serie de ecuaciones:

Si quisiéramos resolverlo, podemos trabajar hacia atrás y enchufarlo.
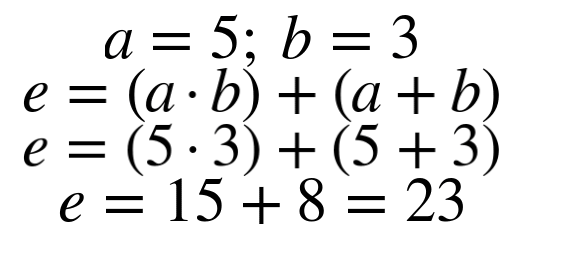
Con eso, el cálculo está completo! Hay conceptos que vale la pena señalar aquí:
- El patrón de uso de nodos de "entrada" es útil, ya que nos permite transmitir un solo valor de entrada a una gran cantidad de nodos futuros. Si no hiciéramos esto, el cliente (o quien haya pasado los valores iniciales) tendría que pasar implícitamente cada valor de entrada a múltiples nodos en nuestro gráfico. De esta manera, el cliente solo tiene que preocuparse por pasar los valores apropiados una vez y cualquier uso repetido de esas entradas se abstrae. Vamos a tocar un poco más en la abstracción de gráficos en breve.
- Pop quiz: ¿Qué nodo se ejecutará primero: el nodo de multiplicación c, o el nodo de adición d? La respuesta: no se puede decir. De solo este gráfico, es imposible saber cuál de c y d se ejecutará primero. Algunos pueden leer el gráfico de izquierda a derecha y de arriba a abajo y simplemente asumir que el nodo c se ejecutará primero, pero es importante tener en cuenta que el gráfico podría haberse dibujado fácilmente con d encima de c. Otros pueden pensar que estos nodos se ejecutan simultáneamente, pero eso puede no siempre será el caso, debido a varios detalles de implementación o limitaciones de hardware. En realidad, es mejor pensar que se ejecutan de forma independiente entre sí. Debido a que el nodo c no se basa en ninguna información del nodo d, no tiene que esperar a que el nodo d haga nada para completar su operación. Lo contrario también es cierto: el nodo d no necesita ninguna información del nodo c. Hablaremos más sobre la dependencia más adelante en este capítulo. A continuación, aquí hay una versión ligeramente modificada de la gráfica:
Hay dos cambios principales aquí:
- El valor de "entrada" 3 del nodo b ahora se pasa al nodo e.
- La función "agregar" en el nodo e ha sido reemplazada por "suma", para indicar que agrega más de dos números.
Observe cómo podemos agregar un borde entre nodos que parecen tener otros nodos "en el camino". En general, cualquier nodo puede pasar a la salida a cualquier nodo futuro en el gráfico, sin embargo, tienen un lugar entre ellos. La gráfica podría tener el siguiente aspecto, y seguir siendo perfectamente válida:

Con estos dos gráficos, podemos comenzar a ver el beneficio de abstraer la entrada del gráfico. Pudimos manipular los detalles precisos de lo que está sucediendo dentro de nuestro gráfico, pero el cliente solo tiene que saber enviar información a los mismos dos nodos de entrada. Podemos extender esta abstracción aún más, y podemos dibujar nuestra gráfica de esta manera:
Al hacer esto, podemos pensar en secuencias completas de nodos como bloques de construcción discretos con un conjunto de entrada y salida. Puede ser más fácil visualizar encadenar grupos de cálculos en lugar de tener que preocuparse por los detalles específicos de cada pieza.
Dependencias
Hay ciertos tipos de conexiones entre nodos que no están permitidos, el más común de los cuales es uno que crea una dependencia circular no resuelta. Para explicar una dependencia circular, vamos a ilustrar qué es una dependencia. Echemos un vistazo a este gráfico de nuevo:
El concepto de dependencia es sencillo: cualquier nodo, A, que se requiere para el cálculo de una posterior se dice que el nodo, B, es una dependencia de B. Si un nodo A y un nodo B no necesitan ninguna información entre sí, se dice que son independientes. Para representar esto visualmente, echemos un vistazo a lo que sucede si el nodo de multiplicación c no puede finalizar su cálculo (por cualquier motivo):
Como era de esperar, dado que el nodo e requiere la salida del nodo c, no puede realizar su cálculo y espera indefinidamente a que lleguen los datos del nodo c. Es bastante fácil ver que los nodos c y d son dependencias del nodo e, ya que introducen información directamente en la función de adición final.
Sin embargo, puede ser un poco menos obvio ver que las entradas a y b son también dependencias de e. ¿Qué sucede si una de las entradas no pasa sus datos a las siguientes funciones en el gráfico?
Sin embargo, puede ser un poco menos obvio ver que las entradas a y b son también dependencias de e. ¿Qué sucede si una de las entradas no pasa sus datos a las siguientes funciones en el gráfico?
Como puede ver, la eliminación de una de las entradas impide que la mayoría de los cálculos se produzcan realmente, y esto demuestra la transitividad de las dependencias. Es decir, si A depende de B y B depende de C, entonces A depende de C. En este caso, el nodo final e depende de los nodos c y d, y los nodos c y d son ambos depende del nodo de entrada b. Por lo tanto, el nodo final e es dependiente de el nodo de entrada b. Podemos hacer el mismo razonamiento para que el nodo e también sea dependiente del nodo a. Además, podemos hacer una distinción entre las diferentes dependencias que e tiene:
- Podemos decir que e depende directamente de los nodos c y d. Con esto, queremos decir que los datos deben provenir directamente de los nodos c y d para que el nodo e se ejecute.
- Podemos decir que e depende indirectamente de los nodos a y b. Esto significa que las salidas de a y b no se alimentan directamente al nodo e. En su lugar, sus valores se introducen en un nodo (s) intermediario que también es una dependencia de e, que puede ser una dependencia directa o una dependencia indirecta. Esto significa que un nodo puede ser depende indirectamente de un nodo con muchas capas de intermediarios intermedios (y cada uno de esos intermediarios también es una dependencia).
Finalmente, veamos qué sucede si redireccionamos la salida de un gráfico a una parte anterior:
Bueno, desafortunadamente parece que eso no va a volar. Ahora estamos intentando pasar la salida del nodo e nuevamente al nodo b y, con suerte, tener el ciclo del gráfico a través de sus cálculos. El problema aquí es que el nodo b ahora tiene el nodo e como una dependencia directa, mientras que al mismo tiempo, el nodo e depende del nodo b (como se mostró anteriormente). El resultado de esto es que ni b ni e pueden ejecutarse, ya que ambos esperan que el otro nodo complete su cálculo.
Quizás sea inteligente y decida que podríamos proporcionar algún estado inicial al valor que alimenta a b o e. Es nuestra gráfica, después de todo. Vamos a darle una patada al gráfico dando a la salida de e un valor inicial de 1:
Así es como se ven los primeros bucles a través del gráfico. Crea un bucle de retroalimentación sin fin, y la mayoría de los bordes en el gráfico tienden hacia el infinito. ¡Ordenado! Sin embargo, para software como TensorFlow, este tipo de bucles infinitos son malos por varias razones:
- Debido a que es un bucle infinito, la terminación del programa no va a ser elegante.
- El número de dependencias se vuelve infinito, ya que cada iteración subsiguiente depende de todas las iteraciones anteriores. Desafortunadamente, cada nodo no cuenta como una sola dependencia, cada vez que su salida cambia los valores, se cuenta nuevamente. Esto hace que sea imposible realizar un seguimiento de información de dependencia, que es crítica por varios motivos (consulte el final de esta sección).
- Frecuentemente terminas en situaciones como este escenario, donde los valores que se transmiten explotan en grandes números positivos (donde eventualmente se desbordarán), grandes números negativos (en los que finalmente irás por debajo del flujo), o se acercarán a cero (en qué punto Cada iteración tiene poco significado adicional).
Debido a esto, las dependencias realmente circulares no se pueden expresar en TensorFlow, lo cual no es algo malo. En el uso práctico, simulamos este tipo de dependencias copiando un número finito de versiones de la gráfica, colocándolas una al lado de la otra y colocándolas una en la otra.
en secuencia. Este proceso se conoce comúnmente como "desenrollar" el gráfico y se tratará más en el capítulo sobre redes neuronales recurrentes. Para visualizar cómo se desenrolla gráficamente este desenrollamiento, aquí se verá cómo se vería el gráfico después de haber desenrollado esta dependencia circular 5 veces:
Si analiza este gráfico, descubrirá que esta secuencia de nodos y bordes es idéntica a recorrer el gráfico anterior 5 veces. Observe cómo los valores de entrada originales (representados por las flechas que saltan a lo largo de la parte superior e inferior del gráfico) se pasan a cada copia a medida que son necesarios para cada "iteración" copiada a través del gráfico. Al desenrollar nuestro gráfico como este, podemos simular dependencias cíclicas útiles manteniendo un cálculo determinístico.
Si analiza este gráfico, descubrirá que esta secuencia de nodos y bordes es idéntica a recorrer el gráfico anterior 5 veces. Observe cómo los valores de entrada originales (representados por las flechas que saltan a lo largo de la parte superior e inferior del gráfico) se pasan a cada copia a medida que son necesarios para cada "iteración" copiada a través del gráfico. Al desenrollar nuestro gráfico como este, podemos simular dependencias cíclicas útiles manteniendo un cálculo determinístico.
Ahora que entendemos las dependencias, podemos hablar sobre por qué es útil hacer un seguimiento de ellas. Imaginemos por un momento que solo queríamos obtener la salida del nodo c del ejemplo anterior (el nodo de multiplicación). Ya hemos definido el gráfico completo, incluido el nodo d, que es independiente de c, y el nodo e, que aparece después de c en la grafico. ¿Tendríamos que calcular el gráfico completo, aunque no necesitamos los valores de d y e? ¡No! Con solo mirar la gráfica, puede ver que sería una pérdida de tiempo calcular todos los nodos si solo queremos la salida de c. La pregunta es: ¿cómo nos aseguramos de que nuestra computadora solo calcule los nodos necesarios sin tener que decirlo a mano? La respuesta: ¡usa nuestras dependencias!
El concepto detrás de esto es bastante simple, y lo único que tenemos que asegurarnos es que cada nodo tenga una lista de los nodos de los que depende directamente (no indirectamente). Comenzamos con una pila vacía, que eventualmente contendrá todos los nodos que queremos ejecutar. Comience con los nodos de los que desea obtener el resultado. Obviamente debe ejecutarse, así que lo agregamos a nuestra pila. Nos fijamos en la lista de dependencias de nuestro nodo de salida
lo que significa que esos nodos deben ejecutarse para calcular nuestra salida, por lo que los agregamos a la pila. Ahora observamos todos esos nodos y vemos cuáles son sus dependencias directas y las agregamos a la pila. Continuamos este patrón hasta el final en el gráfico hasta que no queden dependencias para ejecutar, y de esta manera garantizamos que tenemos todos los nodos que necesitamos para ejecutar el gráfico, y solo esos nodos. Además, la pila se ordenará de manera que se nos garantice que podamos ejecutar cada nodo en la pila a medida que la recorremos. Lo principal a tener en cuenta es hacer un seguimiento de los nodos que ya se calcularon y almacenar su valor en la memoria, de esa manera no calculamos el mismo nodo una y otra vez. Al hacer esto, podemos asegurarnos de que nuestro cálculo sea lo más eficiente posible, lo que puede ahorrar horas de tiempo de procesamiento en gráficos enormes.
Comentarios
Publicar un comentario