¿Recuerdas los cursos de ciencias en la escuela primaria?




Podría haber sido hace un tiempo, o quien sabe, tal vez esté en la escuela primaria y comience su viaje hacia el aprendizaje automático temprano.
De cualquier manera, ya sea que tomes biología, química o física, una técnica común para analizar
los datos en como el cambio de una variable afecta a la otra.
Imagine trazar la correlación entre la frecuencia de la lluvia y la producción agrícola.
Puede observar que un aumento en la precipitación produce un aumento en la tasa de agricultura. Ajustando una linea a estos puntos de datos le permite hacer predicciones sobre la tasa de agricultura bajo diferentes condiciones de lluvia. Si descubre la función subyacente a partir de unos pocos puntos de datos, entonces la función aprendida le permite realizar predicciones sobre los valores de datos invisibles.
La regresión es el estudio de cómo ajustar mejor una curva para resumir sus datos. Es una de los
tipos de algoritmos de aprendizaje supervisado más potentes y bien estudiados. En regresión, intentamos para entender los puntos de datos descubriendo la curva que podría haberlos generado.
Al hacerlo, buscamos una explicación de por qué los datos dados están dispersos de la forma en que están. El mejor ajuste de una curva nos proporciona un modelo para explicar cómo se podría haber producido el conjunto de datos.
Notación Formal
En este capítulo se demostrará la primera herramienta principal de aprendizaje automático, la regresión, y la define formalmente usando cálculos matemáticos precisos.
Aprender primero la regresión es una gran idea, porque muchas de las habilidades que desarrollarás
serviran par resolver problemas discutidos en capítulos futuros. Al final de este capítulo,
la regresión se convertirá en el "martillo" en su caja de herramientas de aprendizaje automático.
Digamos que tenemos datos sobre cuánto dinero gastan las personas en botellas de cerveza. Alice pasó $2 en 1 botella, Bob gastó $4 en 2 botellas y Clair gastó $6 en 3 botellas.
Queremos encontrar una ecuación que describe cómo el número de botellas afecta el costo total. Por ejemplo, si cada botella de cerveza cuesta $2, entonces la ecuación lineal y = 2x puede describir el costo de comprar un producto en particular número de botellas.
Cuando una línea parece ajustarse bien a algunos puntos de datos, podríamos afirmar que nuestro modelo lineal funciona bien. En realidad, podríamos haber probado muchas pendientes posibles en lugar de elegir el valor 2. La elección de la pendiente es el parámetro, y la ecuación producida es el modelo. Hablando en términos de aprendizaje automático, la ecuación de la curva de mejor ajuste proviene del aprendizaje de los parámetros de un modelo.
Como otro ejemplo, la ecuación y = 3x también es una línea, excepto con una pendiente más pronunciada. Tú puede reemplazar ese coeficiente con cualquier número real, llamémoslo w, y la ecuación seguirá produciendo una línea: y = wx. La Figura 3.1 muestra cómo al cambiar el parámetro w afecta el modelo. El conjunto de todas las ecuaciones que podemos generar de esta manera se denota M = {y = wx | w ∈ ℝ } Se lee "Todas las ecuaciones y = wx, de manera que w es un número real".

M es un conjunto de todos los modelos posibles. Elegir un valor para w genera un modelo candidato M(w): y = wx. Los algoritmos de regresión que escribiremos en TensorFlow convergerán iterativamente a mejores y mejores valores para el parámetro w del modelo.
Un parámetro óptimo, llamémoslo w * (pronunciada como w estrella), es la ecuación de mejor ajuste M (w *): y = w * x.
En el sentido más general, un algoritmo de regresión intenta diseñar una función, llamémosla f,
que mapea una entrada a una salida. El dominio de la función es un vector de valor real ℝ a la d y su rango es el conjunto de los números reales ℝ
¿SABÍAS?
La regresión también puede plantearse con múltiples salidas, en lugar de una sola real
número. En ese caso, lo llamamos Regresión Multivariada.
La entrada de la función puede ser continua o discreta. Sin embargo, la salida debe ser
Continuo, como lo demuestra la figura 3.2.

By The Way La regresión predice salidas continuas, pero a veces eso es una exageración. A veces simplemente desea predecir una salida discreta, como 0 o 1, pero nada intermedio.
La clasificación es una técnica mejor adecuado para tales tareas, y será discutido en el siguiente capitulo.
Nos gustaría descubrir una función f que coincida bien con los puntos de datos dados, que son
Básicamente pares de entrada / salida. Desafortunadamente, el número de funciones posibles es infinito, por lo que no tendremos suerte probándolos uno por uno. Tener demasiadas opciones disponibles para elegir por lo general es una mala idea. Nos corresponde restringir el alcance de todas las funciones con las que queremos trabajar, por ejemplo, si solo observamos líneas rectas para ajustar un conjunto de puntos de datos, entonces la búsqueda se vuelve mucho más fácil.
EJERCICIO 3.1 ¿Cuántas funciones posibles existen que asignan 10 enteros a 10 enteros? Por ejemplo, vamos f(x) es una función que puede tomar los números del 0 al 9 y producir los números del 0 al 9. Un ejemplo es la función de identidad que imita su entrada, por ejemplo, f(0) = 0, f(1) = 1, y así sucesivamente. ¿Cuantos otras funciones más existen?
RESPUESTA 10 ^ 10 = 10,000,000,000
¿Cómo sabes que el algoritmo de regresión está funcionando?
Digamos que estamos tratando de vender un algoritmo de predicción del mercado de la vivienda a una empresa de bienes raíces. Eso predice los precios de la vivienda teniendo en cuenta algunas propiedades, como el número de habitaciones y el tamaño del lote. Real las compañías inmobiliarias pueden hacer millones fácilmente con esa información, pero necesitan alguna prueba que realmente funciona antes de comprarte el algoritmo. Para medir el éxito del algoritmo de aprendizaje, deberá comprender dos importantes conceptos: varianza y sesgo.
• La varianza es cuan sensible a una predicción del conjunto de datos de entrenamiento que se usó. Idealmente, como nosotros elegir el conjunto de entrenamiento no debería importar, lo que significa que se desea una varianza más baja.
• El sesgo (bias) es la fuerza de las suposiciones sobre el conjunto de datos de entrenamiento. Haciendo demasiados suposiciones se puede dificultar la generalización, por lo que también preferimos un sesgo bajo. Si un modelo es demasiado flexible, puede memorizar accidentalmente los datos de entrenamiento en lugar de resolver los patrones útiles. Puedes imaginar una función con curvas pasando por cada punto de un conjunto de datos, aparentemente no produce ningún error. Si eso sucede, decimos que el algoritmo de aprendizaje se adapta a los datos.
En este caso, la curva de mejor ajuste coincidirá con los datos de entrenamiento; sin embargo, puede mostrar un cambio abismal cuando se evalúa con los datos de prueba (ver figura 3.3).

En el otro extremo del espectro, un modelo no tan flexible puede generalizarse mejor a datos de pruebas invisibles, pero obtendría una puntuación relativamente baja en los datos de entrenamiento.
Esa situación se llama por debajo de la adaptación "underfitting" un modelo demasiado flexible tiene una alta varianza y bajo sesgo, mientras que un modelo demasiado estricto tiene baja varianza y alto sesgo.
Idealmente, nos gustaría un modelo con un error de varianza baja y error de sesgo bajo. De esa manera, se generaliza a los datos invisibles y captura las regularidades de la datos. Consulte la figura 3.4 para ver ejemplos de un modelo que se adapta y sobrecalienta a los puntos de datos en 2D.
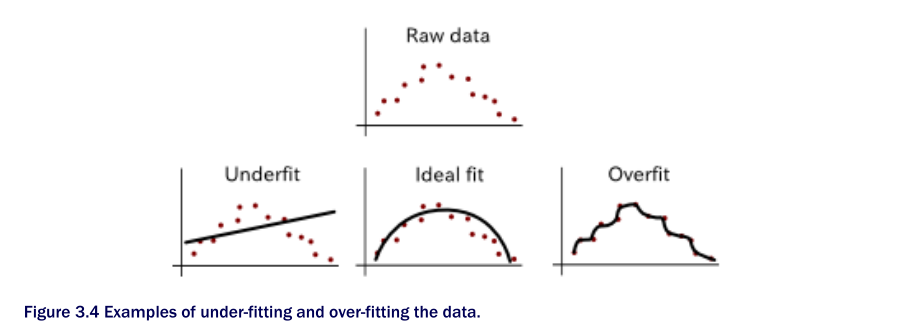
Concretamente, la varianza de un modelo es una medida de qué tan mal fluctúan las respuestas, y
el sesgo es una medida de qué tan mal se compensa la respuesta de la verdad fundamental.
Necesitas un modelo para lograr resultados precisos (bajo sesgo) y reproducibles (baja varianza).
EJERCICIO 3.2
Digamos que nuestro modelo es M (w): y = wx. ¿Cuántas funciones posibles puedes generar si
los valores de los parámetros de peso w deben ser enteros entre 0 y 9 (inclusive)?
RESPUESTA
Solo 10. A saber, {y = 0, y = x, y = 2x,…, y = 9x}.
En resumen, medir el rendimiento de su modelo con datos de entrenamiento no es una buena idea.
Indicador de su generalización. En su lugar, deberías evaluar tu modelo en una sección separada con lotes/sets de datos de prueba y se podría descubrir que en este caso se desempeña terriblemente en los datos de prueba, en ese caso su modelo probablemente se adapto demasiado a los datos de entrenamiento. Si el error de prueba está realmente alrededor igual que el error de entrenamiento, y ambos errores son similares, entonces su modelo probablemente sea por debajo de la adaptación (underfitting).
Por eso, para medir el éxito en el aprendizaje automático, dividimos el conjunto de datos en dos
grupos:
Un conjunto de datos de entrenamiento y un conjunto de datos de prueba.
El modelo se aprende utilizando el conjunto de datos de entrenamiento/capacitación y el rendimiento se evalúa en el conjunto de datos de prueba (exactamente cómo evaluamos
El rendimiento se describirá en la siguiente sección).
De los muchos parámetros de peso posibles que podemos generar, el objetivo es encontrar el que mejor se ajuste a los datos. La forma en que medimos "mejor ajuste"
es mediante la definición de una función de costo, que se trata con mayor detalle en la sección 3.2
Comentarios
Publicar un comentario